Decision Tree and k-Nearest Neighbors Learning
Entropy
1. Shannon information
- $ p $ is the probability of the event
- Event with smaller probability contains more information.
- Logrithm base is 2 beacause in information technology 1 bit represents “0” or “1”.
It can also be regarded as how many bits we need to represent a random variable
For example, when one variable has 8 possibilities. Each of them has a probability of 1/8. Then we need $ \log_2{8} = 3 $ bits to represent the variable.
2. Shannon entropy
- $ H $ is sum of all possible events
H = 1means completly uncertain about the result.H = 0means the result is known.
For example, if we throw a coin, it will have 2 results, both probabilities is 0.5.
The result is totally uncertain.
3. Information gain
- $ H(T|a) $ is the conditional entropy of T given the value of attribute a.
ID3 (Iterative Dichotomiser 3) Algorithm
ID3 is an algorithm invented by Ross Quinlan used to generate a decision tree from a dataset.
It can be used for dataset with categorical features like:
| Day | Outlook | Temperature | Humidity | Wind | Play ball |
|---|---|---|---|---|---|
| D1 | Sunny | Hot | High | Weak | No (-) |
| D2 | Sunny | Hot | High | Strong | No (-) |
| D3 | Overcast | Hot | High | Weak | Yes (+) |
| D4 | Rain | Mild | High | Weak | Yes (+) |
| D5 | Rain | Cool | Normal | Weak | Yes (+) |
| D6 | Rain | Cool | Normal | Strong | No (-) |
| D7 | Overcast | Cool | Normal | Strong | Yes (+) |
| D8 | Sunny | Mild | High | Weak | No (-) |
Pseudocode:
1 | ID3 (Examples, Target_Attribute, Attributes) |
ID3 does not guarantee an optimal solution. It can converge upon local optima. It uses a greedy strategy by selecting the locally best attribute to split the dataset on each iteration.
C4.5 Algorithm
It can be used for data with continuous features.
Procedure:
- Sort the data records by the attribute values
- Calculate the partition point for 2 consecutive records by $ (v_i + v_{i+1})/2 $
- Partition the records into 2 sets by that partition point
- Calculate the entropy reduction (information gain) of the resulting partitions
- If all partition points are calculated, choose the point that yields the highest entropy reduction. Otherwise, ad i by 1 and go back to
step 2
The whole process is nearly the same as ID3 algorithm, except for continuous feature, we need to calculate the partition point. But in ID3 algorithm, we can directly use the categories to split records.
k-Nearest Neighbors Algorithm
Distance between instance i and j
is the feature value of instance $ x $.
To predict a new instance $ x^{(q)} $:
1. Continues value
2. Discrete values
We can also use distance weighted nearest neighbor algorithm:
Evaluation Classification
1. Evaluation Metrics
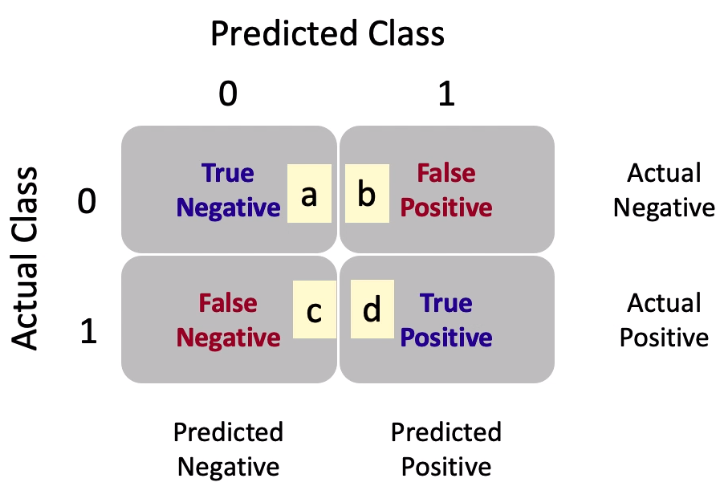
2. Area Under ROC Curve (AUC)
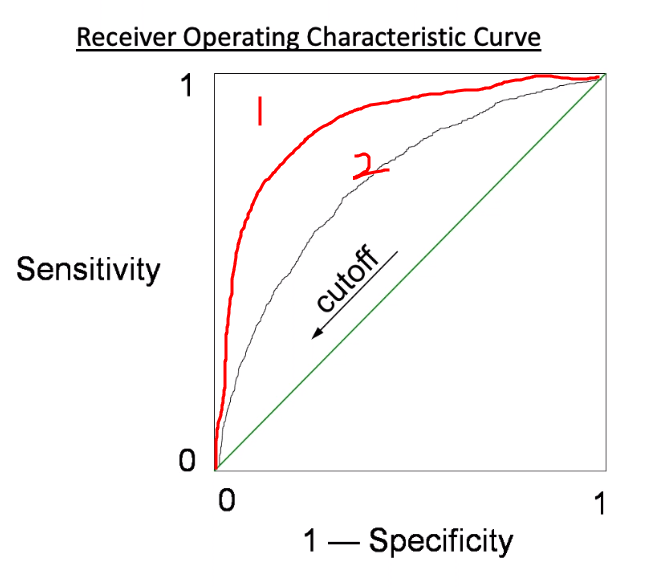
- Cutoff is the threshold a classification model uses to split between 2 classes.
- As the cutoff decreases, more and more cases are classified as 1; hence, the sensitivity increases and speificity decreases.
- As the ROC curvebows above the diagonal, the predictive power increases. Curve 1 is better than curve 2
Issues in Decision Tree Learning
1. Features with many unique values
Problem: Gain tends to select features with many unique values to clssify instance.
Solution: Adjust Gain to GainRatio
$ S $ is the set of all records in a prarent node. $ S_i $ is a subset of records that have feature $ A_i $
When should Gain Ratio be used in place of Gain?
- Compute both Gain Ratio and Gain for each feature
- Use Gain Ratio only for features with above-average Gain
2. Overfitting
Ways to avoid overfitting:
- Stop growing tree when data split is not statistically significant.
- Grow full tree then post-prune.
Selecting best tree:
- Measure performance over taining data
- Measure performance over seperate validation datases
- Add penalty against complexity
3. Unknown feature values
Strategies to impute missing values of feature A:
- Use most common value of A in all instances having missing value for A
- Within each group of instances having same target value, assign most common value of A to instances
